
Una possibile analisi dei testi consiste nel rilevare aspetti numerici delle parole, con cui articoliamo un pensiero: struttura della frase, ampiezza del dizionario che utilizziamo, ripetitività.
A mio giudizio nessuna analisi numerica ci potrà dire se scriviamo bene o male. A farlo ci prova Google, quando decide come posizionare i nostri articoli in una ricerca Web, oppure WordPress, quando ci suggerisce come modificare il testo che abbiamo introdotto, per aumentarne la leggibilità. Ma il giudizio definitivo rimane a chi legge, ed è in larga parte soggettivo.
Non di meno, l’analisi dei testi che produciamo fornisce qualche interessante spunto di riflessione sulla lingua italiana e su come la utilizziamo quando scriviamo.
Per chi, poi, volesse mettersi alla prova, suggerisco il test dell’Università di Ghent e degli Studi di Milano-Bicocca.
I passi di un’analisi dei testi
Il punto di partenza è una base di testi scritti da una stessa persona. Nel mio caso ho scelto dieci post pubblicati qui, su Inchiostro Virtuale:
- L’età del capitano, ovvero: la Matematica è proprio incomprensibile?
- La bella Nicole Lepaute e la cometa di Halley
- Sophie Germain e Monsieur Le Blanc
- Lenna Sjööblom, la First Lady di Internet
- Maria Stuarda, quando la sicurezza informatica fa cilecca
- Self-driving car: siamo pronti?
- Puzzle of the week, e il divertimento è assicurato
- Matematica in fumo: sigarette, sigari, pipe e fiammiferi
- Numeri palindromi e altre noiosità
- Flat Earth: il Sole gira sopra di noi?
Fanno circa 16.000 parole scritte negli ultimi 18 mesi, suppergiù, e su argomenti relativamente vari, visto che girano quasi sempre intorno a numeri.
Il primo passo è quello di estrarre dai testi le parole utilizzate e sintetizzarne gli aspetti numerici in un file, da analizzare successivamente con il classico programma Libre Office Calc o con Excel. Per questo scopo ho preparato un programma in Ruby, rudimentale (non distingue le parole italiane da quelle inglesi, ad esempio) ma decisamente semplice.
Il passo successivo è l’elaborazione con Libre Office Calc, con la produzione di alcuni grafici di sintesi.
Il programma in Ruby
La struttura del programma è abbastanza semplice: per ogni articolo di una lista, si isolano, linea per linea, le parole di testo. Successivamente si calcola, per ogni parola individuata, il numero di occorrenze sia nel singolo articolo che nell’insieme degli articoli della lista.
Per individuare le singole parole si utilizza il metodo .split() che, applicato a una linea, ne pone in un array le singole parole presenti.
Come si fa a estrarre le singole parole?
Ci vengono in aiuto le regular expression, per istruire il programma su come individuare il separatore tra le singole parole.
Separatori naturali sono gli spazi e i segni di interpunzione, ma vanno considerati separatori anche le cifre numeriche ed eventuali caratteri speciali utilizzati nei testi (ho aggiunto degli spazi per leggibilità):
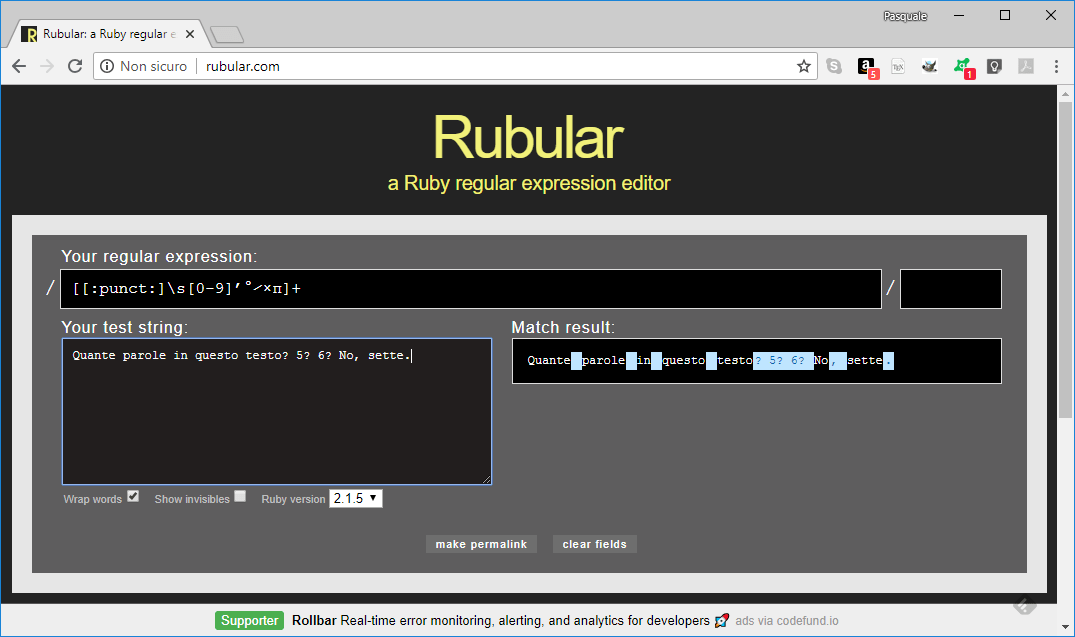
split( / [ [:punct:] \s [0-9] ’ ° ⁄ × π ] + /)
La coppia di parentesi quadre più esterna racchiude i possibili caratteri separatori: la classe dei segni di interpunzione, per fortuna predefinita, gli spazi (\s), le cifre numeriche ([0-9]). Va poi aggiunto l’apostrofo sexy di WordPress, inclinato all’indietro, oltre a una manciata di caratteri speciali che utilizzo di tanto in tanto.
Il segno + finale indica che più caratteri separatori successivi vanno raggruppati in un solo separatore. Quindi, ad esempio, la linea:
Quante parole in questo testo? 5? 6? No, sette.
considererà “? 5? 6? ” come un unico separatore, e così “, “, lasciando quindi esattamente 7 parole.
Nota: l’algoritmo utilizzato è semplice ma rozzo nelle conclusioni. Un esempio: entrambe le grafie “nondimeno” e “non di meno” sono corrette, ma contribuiscono in modo decisamente diverso alla ricchezza del dizionario.
Le regular expression sono bestie complesse a piacere, un aiuto nella messa a punto è decisamente gradita. La pagina rubular.com è perfetta allo scopo.
Passo successivo: costruzione del dizionario
Qui viene in aiuto la struttura hash di Ruby.
In inglese hash sta per sminuzzare, pasticciare. Mai assaggiati gli hash brown potatoes a colazione?
Nel campo dell’informatica, l’hash è una funzione che riduce una stringa di lunghezza variabile a una chiave di lunghezza fissa e generalmente minore di quella della stringa di partenza.
L’hash di Ruby è invece una struttura dati che consente di associare dei valori a una stringa data, mediante una funzione di hash.
Ad esempio:
diz = Hash.new(0)
definisce “diz” come una struttura hash, inizializzata con il valore 0.
diz[“domani”] += 1
incrementa di 1 il valore contenuto in diz[“domani”], che può essere quindi utilizzato per contare le occorrenze della parola “domani”.
Ultimo dettaglio relativo al programma: per pigrizia e per semplicità, il programma va eseguito una volta, per determinare i dizionari di ciascun articolo, e un’altra per calcolare il dizionario aggregato. Basta modificare il valore della variabile “dettagli” (= 0, dizionario unico, = 1 un dizionario per articolo).
Il programma Ruby per l’analisi dei testi
# Analisi della frequenza delle parole di un testo §
# by p.p. 30 giugno 2018
#
# post
post = [“capitano”, “nicole”, “sophie”, “lenna”, “stuarda”, “self-drive”, “puzzle-week”, “fumo”, “palindromi”, “terra-piatta”]
# dettagli = 1 per stampare un dizionario per post; = 0 per la stampa di un unico dizionario
dettagli = 1
#
# stampa del dizionario utilizzato
def stampa_diz(diz)
diz = diz.sort_by {|chiave, valore| [-valore, chiave]}.to_h
diz.each do |chiave, valore| print chiave.to_s, “, “, valore, “\n”
end
end
#
# costruzione del dizionario utilizzato
diz = Hash.new(0) if dettagli != 1 then print “–> all\n” end
post.each do |titolo|
if dettagli == 1 then diz.clear ; print “–> “, titolo, “\n” end
File.open(titolo +”.txt”).each do |linea|
parole = linea.force_encoding(“UTF-8”).downcase.split(/[[:punct:]\s[0-9]’°⁄×π]+/)
# if parole.include?(“n”) then print titolo, “: “, linea, “\n” end parole.each do |singola|
if singola != “” then diz[singola] += 1 end end end if dettagli == 1 then stampa_diz(diz) end
end
if dettagli != 1 then stampa_diz(diz) end
L’analisi dei testi: quanto è grande il dizionario che usiamo?
L’insieme di parole utilizzate almeno una volta nei testi analizzati costituirà il dizionario.
Oltre al valore numerico (quante parole ci sono nel dizionario?), è interessante verificare con quale tendenza questo valore è destinato a crescere aggiungendo testi. Perché prima o poi avremo esaurito le parole che conosciamo e da lì in avanti ci toccherà ripeterci.
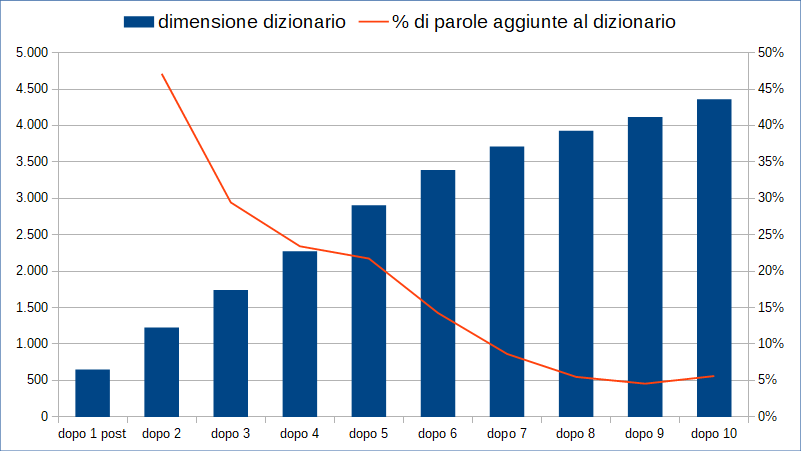 La tendenza si può intravedere se poniamo in un grafico l’incremento percentuale della dimensione del dizionario, dopo 2, 3, … 10 articoli.
La tendenza si può intravedere se poniamo in un grafico l’incremento percentuale della dimensione del dizionario, dopo 2, 3, … 10 articoli.
Si intuisce dal grafico che la crescita del dizionario si ammoscia articolo dopo articolo, crollando dopo 7-8 testi. La piccola ripresa sul decimo articolo è dovuta all’argomento (“Terra piatta”), diverso da quello dei precedenti nove.
Questo effetto è intuitivo, perché ad ogni articolo si aggiungono sempre meno nuove parole, e allo stesso tempo aumenta la lunghezza del dizionario.
Nota: il programma non distingue, come premesso, parole italiane da parole straniere, e nemmeno riconosce declinazioni diverse della stessa parola. Quindi la dimensione di 4.361 parole nel dizionario da me utilizzato nei dieci articoli va presa con le molle. Inoltre l’affermazione che oggi utilizziamo meno di poche centinaia di parole, si riferisce alla lingua parlata, in cui siamo evidentemente più sciatti e ripetitivi, rispetto a quando scriviamo.
Quanto spesso utilizziamo le parole del nostro dizionario?
Poniamo in un grafico il numero di parole utilizzate solo in 1, 2, 3 … 10 articoli.
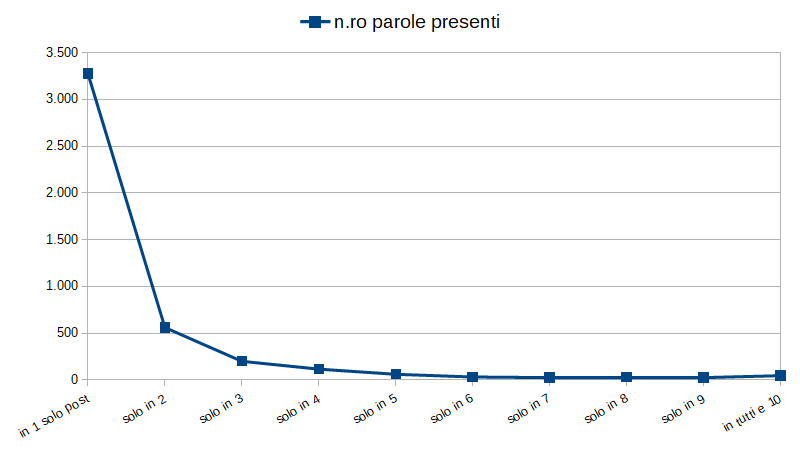 La maggioranza delle parole è stata utilizzata in un solo articolo (3.275) o in due (560). All’altro estremo troviamo le 45 parole utilizzate in tutti e dieci gli articoli. Eccole:
La maggioranza delle parole è stata utilizzata in un solo articolo (3.275) o in due (560). All’altro estremo troviamo le 45 parole utilizzate in tutti e dieci gli articoli. Eccole:
di, la, e, il, a, un, per, che, è, in, si, una, l, con, del, non, della, da, i, al, le, nel, dei, più, ha, se, dell, ma, anche, c, sono, alla, solo, o, quindi, due, gli, come, dal, sul, nella, ad, sua, ci, senza
Sono tutti connettivi, tranne il “due”. Si tratta, cioè, del collante tra parole di significato specifico. Nel discorso queste ultime forniscono la specificità, ma i connettivi ne determinano il senso.
L’assoluto winner è la parola “di“, presente 595 volte, quindi con una media di 60 volte per articolo. Segue “la“, con 360, “e” con 358, e poi via via decrescendo, fino a “senza” con 25 occorrenze.
Mi hanno sorpreso il “due“, presente 41 volte, e la mancanza di “uno“. In realtà “uno” è, con 23 presenze, nel gruppo delle parole presenti in 9 articoli su 10:
anni, esempio, lo, cui, delle, tra, suo, dopo, problema, uno, mi, quando, d, dalla, ne, ogni, perché, quello, volta, così, però, primo, altri
Il post in cui manca è proprio il decimo della lista, Flat Earth: il Sole gira sopra di noi?
Analisi dei testi: quanto pesano i connettivi?
Riportiamo in un grafico il numero di parole distinte presenti in ciascun post, e la percentuale di connettivi sul totale delle parole.
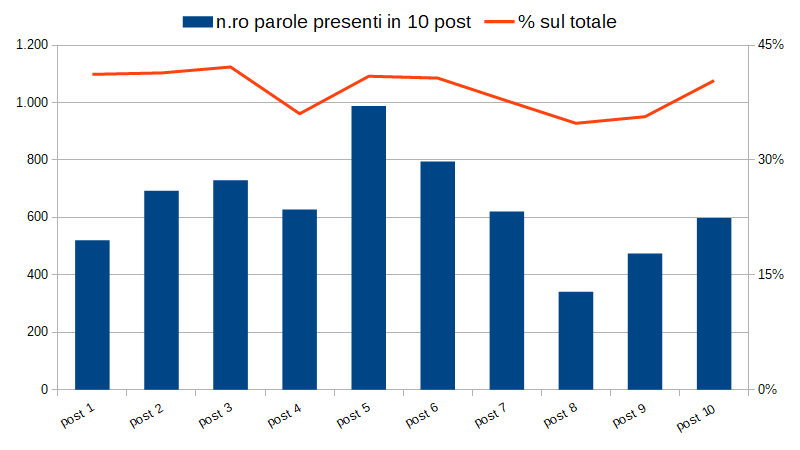
Prima osservazione: ci sono articoli molto ricchi di testo (il n.ro 5: Maria Stuarda, quando la sicurezza informatica fa cilecca) e articoli relativamente poveri (il n.ro 8: Matematica in fumo: sigarette, sigari, pipe e fiammiferi).
In ogni articolo la percentuale di occorrenze di connettivi è ragionevolmente stabile, con variazioni intorno al 40%.
Detto in altri termini, quattro parole su dieci sono connettivi, almeno nei test che scrivo. Sarebbe interessante analizzare qualche mano diversa dalla mia!
Ma, in conclusione, cosa dice del mio dizionario l’analisi dei testi?
Grazie alla pagina delle mille parole più comuni in italiano di Maurizio Codogno, è possibile verificare gli scostamenti del mio dizionario dalla normalità.
Sui connettivi, sembra che il mio utilizzo del termine “di” sia molto più alto della media. Per me è il top, con largo vantaggio su “il“, che invece sembra essere il più diffuso in generale.
Sulle parole di significato specifico, nel mio dizionario per il momento mancano “occhio“, “signore” e “guerra“.
Ma non sarà necessario che uno dei prossimi temi sia legato alla storia, tipo la vicenda di un signore che scatena una guerra, per una vendetta occhio per occhio.
Perché con questo post la lacuna è già colmata!
Articoli correlati:





Mi chiamo Pasquale Petrosino, radici campane, da alcuni anni sulle rive del lago di Lecco, dopo aver lungamente vissuto a Ivrea.
Ho attraversato 40 anni di tecnologia informatica, da quando progettavo hardware maneggiando i primi microprocessori, la memoria si misurava in kByte, e Ethernet era una novità fresca fresca, fino alla comparsa ed esplosione di Internet.
Tre passioni: la Tecnologia, la Matematica per diletto e le mie tre donne: la piccola Luna, Orsella e Valentina.